基于DevOps的开源治理
本文内容选自2021中国DevOps社区峰会 · 大连站,我的演讲内容整理稿。
很高兴来大连跟大家分享我最近的工作,我现在在做公司内部的开源治理,我会讲一个比较大的命题,叫做“软件工程的发展趋势”,就是把软件工程这么多年的发展趋势,按照我的版本来讲讲,看看有没有道理,再讲开源、架构、工程、DevOps的事情,大概是这样的提纲。
软件工程的发展趋势

最早,软件工程的第一个阶段,就是软件工程被提出来的时候,大概是在60年代到80年代的时期,为什么说在1960年代出现了软件危机呢?
是因为在此之前没有几个人真正研究过软件工程,等到开发一些复杂软件的时候,发现软件做不出来了,软件危机的唯一目的就是要按期做出来。
如果超期也不要超太多,所以在那个年代,过去没有思考过软件工程这个事情的时候,那些专家们都是数学家转行过来写软件,我们就向别的工程方法学习。学建筑工程、桥梁工程,瀑布模型就是这样出来的,结构化工程也是这样出来的,这个是第一个时期。
我们可以认为那个年代的软件和软件工程是被军工所驱动,你可以这么理解,那个时候你生产一份软件通常卖给一家,卖给两家都不太可能,很难想象一个软件卖几百万套。
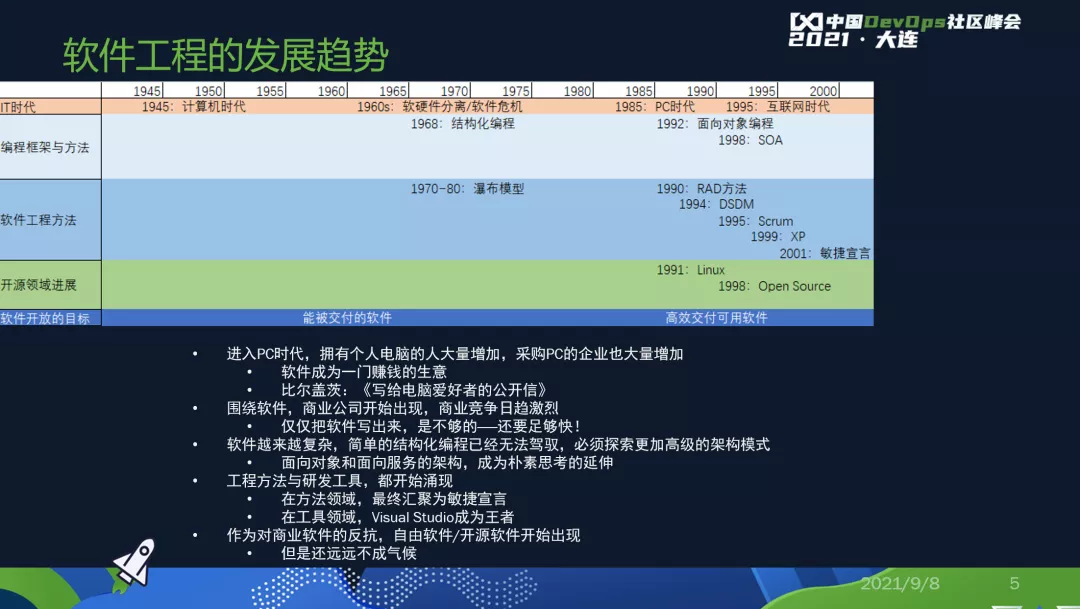
等进入PC时代,个人电脑出来了,大量的企业和个人都开始有了自己的电脑,于是软件成为一门赚钱的生意。
比尔盖茨写了一封信——《写给电脑爱好者的一封信》:你们这些人拿了我的软件就复制给朋友们用,你们号称软件爱好者,你们就是在偷我的钱,你们一直这样干,就没有一家软件公司能够赚到钱,就没有一家软件公司可以帮你们把东西写出来。
当时这封信在电脑爱好者当中产生了剧烈的影响,所以软件行业才起来了,商业软件才出来了。软件才进入到下一个阶段,就是商业软件驱动的软件工程,不仅仅要把软件做出来,交付给军方、NASA等等。
我们要尽快把软件做出来,把更多的功能堆上来,尽快的拿出去卖钱,原来结构化编程不够了,我们要面向对象编程,瀑布模型不够了,我们要从RAD、DSDM、SCRUE、XP到最后的敏捷宣言。
我之所以梳理这样一个版本就是在讲,驱动我们技术领域的、工程领域、方法领域的变革,背后的趋势都是联在一起的。当然,开源领域那时候刚刚出来,一直到1998年Open Source才刚刚出来。
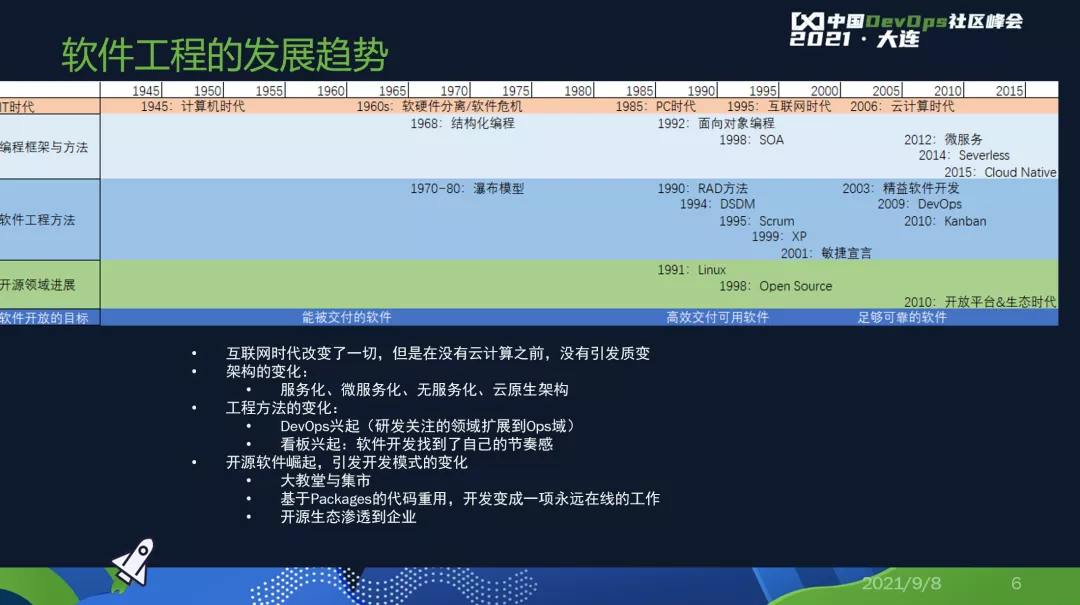
到后来互联网出来了,软件有了什么样的变化?原来做出来是卖给用户的,是在自己的公司里用。现在我们要部署一个服务,要有一个集群服务成千上万的用户。原来的架构不足以支撑这样的用户量,以及这些用户量带来的变化。
首先是云计算出来了,服务化、微服务化、无服务化等等都是被互联网不断增大的压力所逼出来的,编程方法也发生的变化,不光是敏捷宣言,所以DevOps就出来了。
到了云计算这个时代,我们必须这两者一起考虑,所以工程方法出来了,不仅仅是Dev和Ops一起考虑,这些还只是云计算以及相关领域的变化。
另外一个是已经蓬勃兴起的开源软件,这时候开源软件趁着互联网的大潮,开源软件无处不在了,我们所有用到的软件和技术,我们所有探索的任何新的领域都是开源,我们已经绕不开了,开源生态已经渗透到企业的方方面面了。
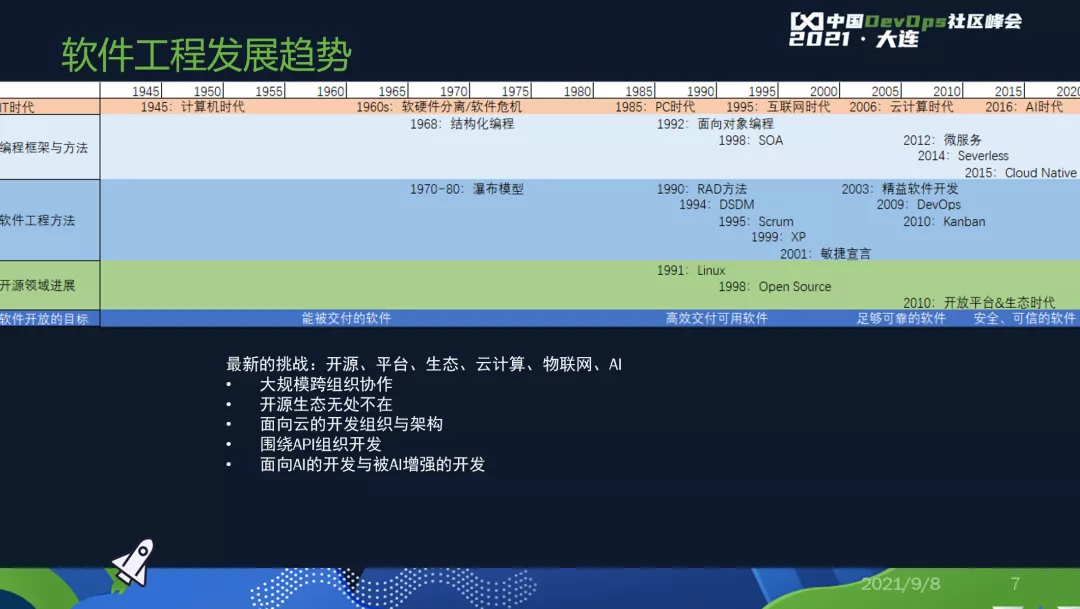
开源吞噬软件之后
所以,最新的挑战是什么?
最新的挑战是我们处在一个被开源逐步吞噬的世界,开源、平台、生态、云计算、物联网、AI大规模跨组织协作,开源生态无处不在,面向云的开发组织与架构,围绕API组织开发,面向AI的开发与被AI增强的开发等等。
这背后所谓安全、可信的软件如何做出来?
这个是一个在网络上截的图,地球那么小,软件正在吞噬世界,开源吞噬软件,云吞噬开源,多云正在吞噬云。如果开源软件这么普及,我们要如何应对?所谓的应对是我们的工程架构,我们的软件架构,我们的组织架构都应该作出什么样的变化?

这个是我从新思科技找到的一张图,他们在2020年审计了1546个代码库,平均每个代码库有158个漏洞,这个漏洞已经进来了,我们还要用,我们不是在一个坚实的地基上写软件,我们在一个不可控的世界上祈祷不要摔跤,扫描到的漏洞平均年龄是2.2岁,就是这个漏洞发生了两年多了,可能你不知道,黑客知道,但是你把它上线了,这就是现实。
我们以为开源是免费的却没有认真地计算:使用开源、维护开源、参与开源社区所需要付出的成本。很多企业,都是被教育的,就是逐渐被线上事故、法律诉讼教育的,才知道开源还有这些麻烦,我们现在需要了解这些事情。

有一个说法,有一个房间里面有一个大象,我们都假装没有这个大象,我们也不去谈论它,但事实上大象一直在房间里,98%的代码库,包含开源代码,75%的代码由开源代码构成。
84%的代码库,至少包含一个漏洞,平均每个代码库,有158个漏洞。最近五年,开源代码的漏洞百分比,均有增加,精确追踪与定位漏洞,依然相当困难。
投入开源的开发者的数量在逐年增长,越来越多的人参与开源代码的开发,意味着越来越多的新手在开源社区里面写代码,他们写出来的代码你就敢用了吗?
稍微有一点不好意思的说,开源代码的整体质量在下降,和开源社区人数不断上升的背后是有因果关系的。还有一些问题,不光是漏洞,还有就是任何开源的软件背后都有许可证。
你们听说过,这些不是互相之间相安无事的,而是冲突的。你用了我的开源软件,你就不能用别的开源软件,你在做开源软件选型的时候,只看功能,我都拿来用,后来发现开源软件有许可证冲突。
还有很多开源软件其实就是一些爱好者,想也没想就把代码给扔出来了,没有许可证(License)就证明没有任何可靠性的承诺,不给你承诺,你怎么就敢用?
所以,超过90%经过审计的代码库,含有许可证冲突、自定义许可证或根本没有许可证。
除了许可证风险的代码库比例依然很高,商业软件中过时的开源组件已成常态。
我们在用开源的时候,我们用各种包管理工具等,一口气引入很多包进来,就编译成功了,过了一年两年,里面用的开源组件没有升级,在社区里面暴露出来的安全漏洞也不看。
91%的被审计代码库中包含:过去两年中没有进行过功能升级、代码优化和任何安全问题修复的依赖项。这就是房间里的大象。
开放性架构与开放性软件工程

但我们是不是不再用开源呢?
这不能是我们的选项,因为开源太香了,那么方便,那么好用,怎么可能不用呢。
今天也是架构专场,我们讨论开放性架构的问题,比如说什么叫拼接与一致性的矛盾?
我们原来做架构师,想当然认为架构都是我们设计的,其实有多少东西不是你的?你只是抓过来放在你的篮子里,可能鸡蛋大小型号不一样,甚至不是一种鸡蛋,你怎么才能把这些组件搭建成一个一致性的架构,让他们相互之间没有冲突,可以让他们配合良好。这个在开源越来越普及的现在,越来越困难。
第二个就是开放性与可靠性的矛盾。我们的代码来自四面八方,而系统运行在开放性的环境里,我们运行在某一个云上面,一层一层往下看都是开源组件,一直到下面的操作系统,上面可能是别的开源。
你想他同时是一个开放式的网络环境,我们如何保证这样的一种开放性的系统和开放性的网络环境在运行过程中是安全可靠的呢?在系统架构中如何考虑进去呢?
第三个就是规划与迭代的矛盾,我们信仰重构和迭代,但是我们从马车重构迭代是不可能获得一辆汽车的,我们有一些风险在一开始做规划设计的就要思考,甚至是艰难的判断取舍这样的事情。
有一个吐槽,我们在很多的技术大会上听到很多成功故事,可为什么我们没有成功?我们给大家的也不是答案,这些问题也很难,在任何一个领域、公司、企业、架构公司里面都是难题,我只是把这些问题说出来了,不能单纯的想如何简单快速地把功能做出来。
下一个问题是一个开放性的架构放在那里,我们软件工程实践如何应对挑战?下面说DevOps的层面。
基于DevOps的开源治理

刚才有一个做医药的兄弟在说,他们项目组的DevOps实践,我想提出一个公司层面的DevOps。
先说项目组,我们这个项目在选型阶段,我们该如何决策这个事情?该引入什么样的开源软件?以及这个软件的质量如何判断?这个是需要重视的。不是我自己的DEMO跑通了就用了。
在使用阶段,要分析我们使用那么多款的开源软件相互的依赖关系,选择了一个组件,甚至有上千个组件会不会连带带进来很多很多的问题,我们如何预防和隔离这些风险,以避免我的选择给我将来制造麻烦。
第三个就是重视修改规范,我们拿了外面的开源软件进来,有时候这些开源软件不够用,我们会去改。
一旦把别人的开源软件改了之后,外面的开源软件还活着,还有新版本出来,你怎么办?下一个版本出来了,你在新版本上再改一遍吗?你的改法跟原来的也不一样。如果要改的话,尽量要正确的修改,加入你的修改回馈到社区,社区是要的。
我们更建议是要主动回馈到社区,这个版本出来改都不要改,因为已经在里面了,这些都是在项目范围内需要考虑的。
下一个问题是企业级的DevOps,我来自华为的开源能力中心,这就真说到我的本职工作了,现在有八万多的研发人员,下面有很多的项目,这些项目多多少少都会用到开源软件,是不是各自都去用了呢?
肯定不行,要在公司范围内做集中管理,我首先要知道,全公司有100个产品,用了12000个开源软件,去重之后只有6000个,大概有100个产品线都在用,只有一个产品在用我也要知道,各自用的版本,这些开源软件的来源是什么?从哪里下载的?如果从正经网站下载就算了,如果从莫名其妙的网站下载我也要知道,有一个白名单的制度,是某某知名开源软件官方网站提供的下载,我要知道他们到底用了什么。
比如说你们产品线用他们的软件的6.0版,另外一个产品用了他们的软件的7.1版,出了某一个安全漏洞,这样一种漏洞通知是使用管理的一个很重要的步骤。
还有一个就是对外回馈,我们真的修改了开源软件,我们要有一个判断,怎么样才能判断如何把这款开源软件某一些修改的部分回馈到社区,这里面非常的复杂的部分是,比如说我们有三个产品线,都改了一个开源软件,比如说OpenSSL的1.1.1版本,他们各自改了不一样的版本,在公司范围内,同一个对于开源软件三个不同的修改,到底归一还是各自管理?
我们有一个委员会,来判断到底是否规范,到底哪些修改是要回归到社区,这个就是公司级的DevOps,尤其是面向开放架构的DevOps管理,细节有很多很多,因为很麻烦。
软件工程的数字化转型
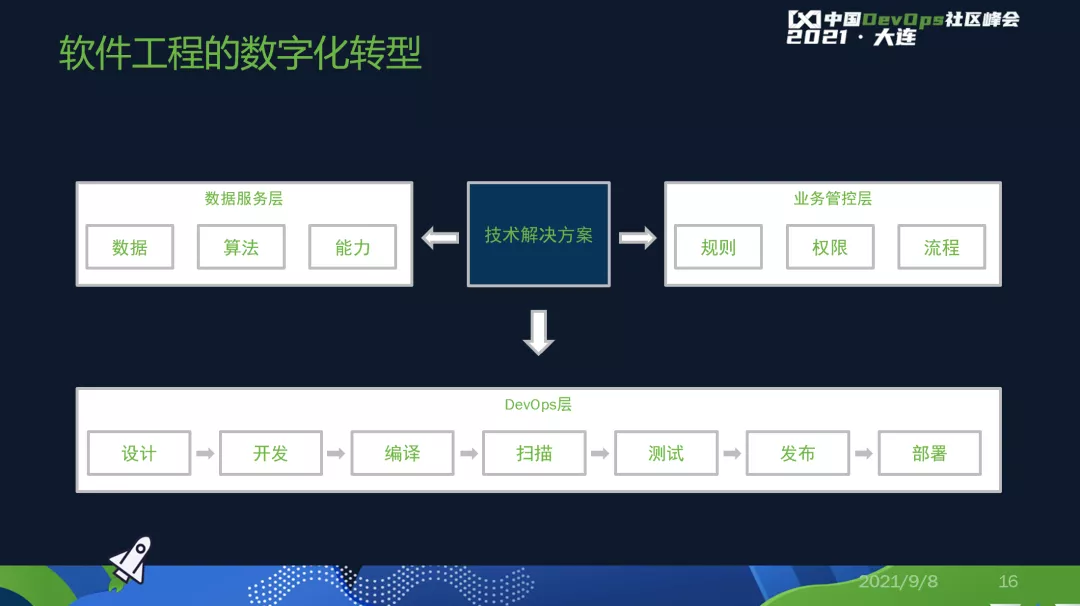
下面回到软件工程的数字化转型,这是一个架构,这个我们在公司里面讲了很多遍,原来DevOps不是解决方案吗?
这个就是公司级的DevOps和我们普通DevOps的最大的区别,我们要建立一个数据服务层和业务管控层,原来在DevOps有很多的工具,比如说各种开源软件、扫描等等工具,都是各自开发或者某一款开源软件的,有采购进来的,也有自己开发的。我们要把所有工具的用户、决策收到统一管控层。一个人有什么样的权限在DevOps下的权限是一致的,否则下一个环节就做不到了,这就是管控层面。
我们要有一个审批的流程,比如说你们部门要用一款新的开源软件,这个新的开源软件要经过一层一层的审批。这个审批通过之后,要有一个工具,从外网把某一个外网仓库的开源软件下载回来,然后再初始化。
这个流程用规则把它固化下来,什么样的级别和什么类型的开源软件,什么样的部门在什么情况下用什么样的开源软件,把这个做成一个公司流程的业务管控层。
同样,我们说数据服务层,我们从外网下载很多的开源软件,到底有多少款?每一款到底什么样?地址是什么?被什么样的人用了?都要独立存放,而且还至少分为两部分数据,一部分是外网的公共数据,一款叫OpenSSL的开源软件等等。
还有一些企业内部数据,基于这些数据,我能够有算法层,我可以做运算甚至是一些AI算法,或者聚类算法,通过算法可以做出一些有价值的报表,这些报表可以看出下面的运行情况。
当然,这些算法以某种数据服务的能力提供出来,最后中间的所谓的技术解决方案,就是要把所有的数据服务层、业务管控层和DevOps串联起来,就是一个最简单的解决方案就是源码初始化,一个团队到业务管控层申请一个开源软件,流程通过了。
从外网抓取,然后初始化,再写到服务层,这一整套完成了,再串联解决方案,这算是一个0层架构,下面展开每一个都非常多的,这个就不多展开了。

我们聊一下数字化转型,我讲的是软件工程的数字化转型,我们针对复杂系统首先追求的是看得见,所有的软件资产集中存放,所有的相关数据集中存在,所有的业务流程集中呈现。都先集中,而这个集中背后的难点是什么?
原来在公司里面有无数大大小小的系统,这里面有无数种的数据,想办法把它的集中放在一起,同类的数据归并到一张表里面,同样的数据归并到一个库里面,这样才叫做看得见,我们跟领导讲这个目标,领导很高兴,我能看见。
如何在一个企业内推数字化转型,就跟领导讲,领导你想不想看见下面什么情况,领导说当然想看见,领导看得见就是第一个需求,我们想办法把数据集中起来再呈现出来。
一个开放性系统如何提升它的管控性?就是管得住。
什么概念?那么多DevOps的系统,里面充满了断裂点。这个环节跟下一个环节需要人工调整或者再改一改,总会有问题,这些断裂点就是我们需要把它补上,把断裂点变成控制点。
我们举一个编译构建的例子,有一个团队这次编译的时候,其中什么JAR包编译进去了,等到我们有一个漏洞中心,突然收到一个消息,外网告诉我们,这个开源软件1.1版有一个安全漏洞,下次编译就不会通过,因为你的开源软件用到了1.1版,你要升级到1.2版才可以通过编译。
我说的这种是非常粗暴的一种策略,但是在整个的DevOps的一个一个的环节当中,我们来通过各种各样的控制策略,把它都能够管控起来,或者是限制、上报、智能修改、智能工具加下来就是管得住。
第三层讲就是自我评价,这个系统到底做的好不好?
首先要定义什么叫管得好,我们想要探索、试错等等,如果这个指标很精准,拿数据的实证模型来验证它,内部组织结构或者内部的系统架构都是清晰的,我们可以创建的是一个实证的模型。
如果系统特别的复杂,甚至可能是一个黑盒状态的话,我们可能猜它内部是一个什么样的东西,我们要做的就是探索模型,看能否探索到这个系统架构。
另外一个说,可以拿来做为经验的就是谈指标的时候,没有用的指标叫做展示型指标。
如果一个指标是1500左右,到底是好还是不好?领导看到的这个1000、1500、2000到底能干什么?什么意义都没有,这个指标拿出来被领导看到,我需要有什么动作。
比如说体温37度我可以不管,但是38度、39度我需要吃药,有这样一个指标展现在领导面前,领导就知道我需要干什么,我们在企业内的各种各样的指标的时候。
指标不是越大越好,指标也不是越漂亮越好,指标要指导我们到底怎么样改变?指标这个事情上来就应该告诉领导,我不知道,我们需要探索。
这个事情你要说我们要一起探索,而不是说在外面找了一个最佳实践,那你就完了。把自己和领导带入到坑里面去了。
我们关注的是结果型指标,结果是最容易判断的,我们对结果指标的应用渐渐有了经验之后,我们反过来反推过程性的指标,但是千万不要一开始就去制定过程性的指标。
这个危险性在于很容易指导团队去做一些看上去漂亮的指标。我们找一个缺陷率,还有测试覆盖率,就是一个过程性的指标。
一个团队追求测试覆盖率的时候,是可以无所不用其极的,我们要做数字化转型的,尤其在研发、工程类的,要看得见、管得住、管得好,要老老实实的告诉领导和团队,我们是需要一起探索的,这样才能做得更好。

除了软件工程领域的数字化转型,比如说我们在工具层面要做转型,同时我们在方法论的层面也要转型。
我们如何探索?如何看待工具?腾讯朋友也说到工具可以帮助企业转型,光靠工具还不够,我们在探索的方式上也要有所尝试和思考,还有就是软件开发的其他领域,不光是软件工程,现在非常热门的智能编程、代码自动补全,这些都是智能化非常早期的阶段。
我们应该假设,整个华为范围内,我们可以拿到所有研发员工相关的数据,包括它的静态数据、行为数据、过程数据,我们全部都拿到,再加上想象力,我们可以做出更多的智能化探索。
今天这个事情就不展开讲了,这完全就是开脑洞的事情,可以搞出很多玩法,今天就不多讲了。
谢谢大家!
Q&A环节
提问1:老师您好,您讲的非常精彩,有一个小问题,关于管理权限,业务管控层面那个,提到说整个环节中比如说同样一个角色,或者不同角色在这个过程中,有相同的组件,比如说测试阶段别人打不开,为什么要有这样的角色?比如说你测试的不是你需要管控的。
庄表伟:比如说有两个工具,一个是代码托管工具,可以触发流水线,触发代码检查工具,这是三个工具,理论上我的权限我的代码提交,就可以触发流水线,如果这个流水线提示我哪里代码报错了,我可以看到报错信息,就是代码检查工具,所谓错的地方的展示信息我也可以看到,否则我这里走不通,因为是三个工具。
提问2:虽然上一位观众也说过了,我还想说一句,非常精彩,DevOps开源治理,目前我想了解一下,咱们华为对于开源治理已经做了哪些比较好的实践?就像刚刚您提到集中管理、资源管理、使用管理、回馈管理,目前有团队落地了,是小范围还是大范围?
庄表伟:这个事情很难,我们已经干了两三年,但还需要再干三两年,涉及到细节,会有无穷无尽的细节,一开始的时间初步可以解决,还有就是效率问题,还有就是一致性问题,诸如此类的,只能慢慢来,绝大多数华为内部的开源软件都可以做到统一管理,但是还没有做完,至少还要做两三年。